
Head over to our on-demand library to view sessions from VB Transform 2023. Register Here
New York City-based artificial intelligence (AI) startup Arthur has announced the launch of Arthur Bench, an open-source tool for evaluating and comparing the performance of large language models (LLMs) such as OpenAI‘s GPT-3.5 Turbo and Meta’s LLaMA 2.
“With Bench, we’ve created an open-source tool to help teams deeply understand the differences between LLM providers, different prompting and augmentation strategies and custom training regimes,” said Adam Wenchel, CEO and cofounder of Arthur, in a press statement.
How Arthur Bench works
Arthur Bench allows companies test the performance of different language models on their specific use cases. It provides metrics to compare models on accuracy, readability, hedging and other criteria.
For those who have used LLMs on more than a few occasions, “hedging” is an especially noticeable issue — that’s where an LLM provides extraneous language summarizing or alluding to its terms of service, or programming constraints, such as saying “as an AI language model…,” which is typically not germane to a user’s desired response.
Event
VB Transform 2023 On-Demand
Did you miss a session from VB Transform 2023? Register to access the on-demand library for all of our featured sessions.
“Those are some of the subtle differences of behaviors that may be relevant for your particular application,” Wenchel said in an exclusive video interview with VentureBeat.
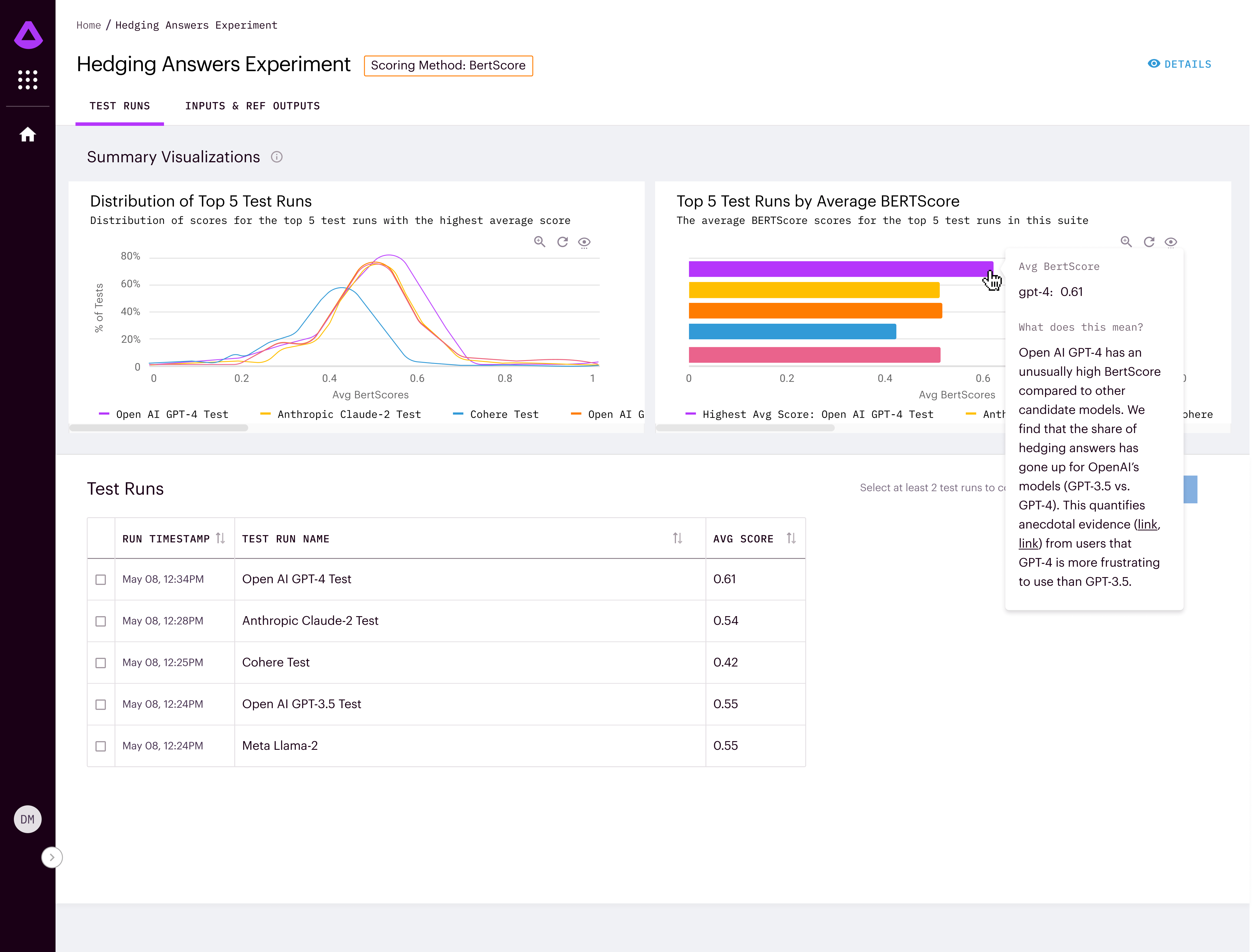
Arthur has included a number of starter criteria upon which to compare LLM performance, but because the tool is open source, enterprises using it may add their own criteria to fit their needs.
“You can grab the last 100 questions your users asked and run them against all models. Then Arthur Bench will highlight where answers were wildly different so you can manually review those,” explained Wenchel, adding that the goal is to help enterprises make informed decisions when adopting AI.
Arthur Bench accelerates benchmarking and translates academic measures into real-world business impact. The company uses a combination of statistical measures and scores as well as the assessment of other LLMs to grade the response of desired LLMs side by side.
Arthur Bench in action
Wenchel said financial-services firms have already been using Arthur Bench to generate investment theses and analyses more quickly.
Vehicle manufacturers have taken their equipment manuals with many pages of highly specific technical guidance and used Arthur Bench to create LLMs that are capable of answering customer queries while sourcing information from said manuals quickly and accurately, all while reducing hallucinations.
Another customer, the enterprise media and publishing platform Axios HQ, is also using Arthur Bench on its product-development side.
“Arthur Bench helped us develop an internal framework to scale and standardize LLM evaluation across features, and to describe performance to the Product team with meaningful and interpretable metrics,” said Priyanka Oberoi, staff data scientist at Axios HQ, in a statement to VentureBeat.
Arthur is open-sourcing Bench so anyone can use and contribute to it for free. The startup believes an open-source approach leads to the best products, with opportunities to monetize through team dashboards.
Collaborations with AWS and Cohere
Arthur also announced a hackathon with Amazon Web Services (AWS) and Cohere to encourage developers to build new metrics for Arthur Bench.
Wenchel said AWS’s Bedrock environment for choosing between and deploying a variety of LLMs was “very philosophically aligned” with Arthur Bench.
“How do you rationally decide which LLMs are right for you?” Wenchel said. “This complements the AWS strategy very well.”
The company launched Arthur Shield earlier this year to monitor large language models for hallucinations and other issues.
Correction, Aug. 17: The author mistakenly stated that Arthur was based in San Francisco. The story has been updated and corrected. We regret the error.
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.





