
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Meta founder and CEO Mark Zuckerberg, who built the company atop of its hit social network Facebook, finished this week strong, posting a video of himself doing a leg press exercise on a machine at the gym on his personal Instagram (a social network Facebook acquired in 2012).
Except, in the video, the leg press machine transforms into a neon cyberpunk version, an Ancient Roman version, and a gold flaming version as well.
As it turned out, Zuck was doing more than just exercising: he was using the video to announce Movie Gen, Meta’s new family of generative multimodal AI models that can make both video and audio from text prompts, and allow users to customize their own videos, adding special effects, props, costumes and changing select elements simply through text guidance, as Zuck did in his video.
The models appear to be extremely powerful, allowing users to change only selected elements of a video clip rather than “re-roll” or regenerate the entire thing, similar to Pika’s spot editing on older models, yet with longer clip generation and sound built in.
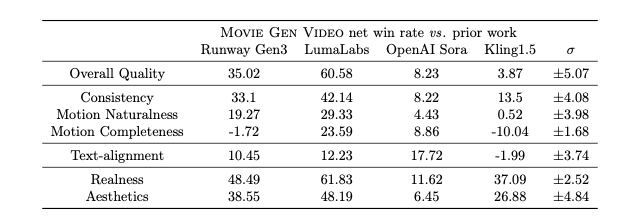
Meta’s tests, outlined in a technical paper on the model family released today, show that it outperforms the leading rivals in the space including Runway Gen 3, Luma Dream Machine, OpenAI Sora and Kling 1.5 on many audience ratings of different attributes such as consistency and “naturalness” of motion.
Meta has positioned Movie Gen as a tool for both everyday users looking to enhance their digital storytelling as well as professional video creators and editors, even Hollywood filmmakers.
Movie Gen represents Meta’s latest step forward in generative AI technology, combining video and audio capabilities within a single system.
Specificially, Movie Gen consists of four models:
1. Movie Gen Video – a 30B parameter text-to-video generation model
2. Movie Gen Audio – a 13B parameter video-to-audio generation model
3. Personalized Movie Gen Video – a version of Movie Gen Video post-trained to generate personalized videos based on a person’s face
4. Movie Gen Edit – a model with a novel post-training procedure for precise video editing
These models enable the creation of realistic, personalized HD videos of up to 16 seconds at 16 FPS, along with 48kHz audio, and provide video editing capabilities.
Designed to handle tasks ranging from personalized video creation to sophisticated video editing and high-quality audio generation, Movie Gen leverages powerful AI models to enhance users’ creative options.
Key features of the Movie Gen suite include:
• Video Generation: With Movie Gen, users can produce high-definition (HD) videos by simply entering text prompts. These videos can be rendered at 1080p resolution, up to 16 seconds long, and are supported by a 30 billion-parameter transformer model. The AI’s ability to manage detailed prompts allows it to handle various aspects of video creation, including camera motion, object interactions, and environmental physics.
• Personalized Videos: Movie Gen offers an exciting personalized video feature, where users can upload an image of themselves or others to be featured within AI-generated videos. The model can adapt to various prompts while maintaining the identity of the individual, making it useful for customized content creation.
• Precise Video Editing: The Movie Gen suite also includes advanced video editing capabilities that allow users to modify specific elements within a video. This model can alter localized aspects, like objects or colors, as well as global changes, such as background swaps, all based on simple text instructions.
• Audio Generation: In addition to video capabilities, Movie Gen also incorporates a 13 billion-parameter audio generation model. This feature enables the generation of sound effects, ambient music, and synchronized audio that aligns seamlessly with visual content. Users can create Foley sounds (sound effects amplifying yet solidifying real life noises like fabric ruffling and footsteps echoing), instrumental music, and other audio elements up to 45 seconds long. Meta posted an example video with Foley sounds below (turn sound up to hear it):
Trained on billions of videos online
Movie Gen is the latest advancement in Meta’s ongoing AI research efforts. To train the models, Meta says it relied upon “internet scale image, video, and audio data,” specifically, 100 million videos and 1 billion images from which it “learns about the visual world by ‘watching’ videos,” according to the technical paper.
However, Meta did not specify if the data was licensed in the paper or public domain, or if it simply scraped it as many other AI model makers have — leading to criticism from artists and video creators such as YouTuber Marques Brownlee (MKBHD) — and, in the case of AI video model provider Runway, a class-action copyright infringement suit by creators (still moving through the courts). As such, one can expect Meta to face immediate criticism for its data sources.
The legal and ethical questions about the training aside, Meta is clearly positioning the Movie Gen creation process as novel, using a combination of typical diffusion model training (used commonly in video and audio AI) alongside large language model (LLM) training and a new technique called “Flow Matching,” the latter of which relies on modeling changes in a dataset’s distribution over time.
At each step, the model learns to predict the velocity at which samples should “move” toward the target distribution. Flow Matching differs from standard diffusion-based models in key ways:
• Zero Terminal Signal-to-Noise Ratio (SNR): Unlike conventional diffusion models, which require specific noise schedules to maintain a zero terminal SNR, Flow Matching inherently ensures zero terminal SNR without additional adjustments. This provides robustness against the choice of noise schedules, contributing to more consistent and higher-quality video outputs .
• Efficiency in Training and Inference: Flow Matching is found to be more efficient both in terms of training and inference compared to diffusion models. It offers flexibility in terms of the type of noise schedules used and shows improved performance across a range of model sizes. This approach has also demonstrated better alignment with human evaluation results.
The Movie Gen system’s training process focuses on maximizing flexibility and quality for both video and audio generation. It relies on two main models, each with extensive training and fine-tuning procedures:
• Movie Gen Video Model: This model has 30 billion parameters and starts with basic text-to-image generation. It then progresses to text-to-video, producing videos up to 16 seconds long in HD quality. The training process involves a large dataset of videos and images, allowing the model to understand complex visual concepts like motion, interactions, and camera dynamics. To enhance the model’s capabilities, they fine-tuned it on a curated set of high-quality videos with text captions, which improved the realism and precision of its outputs. The team further expanded the model’s flexibility by training it to handle personalized content and editing commands.
• Movie Gen Audio Model: With 13 billion parameters, this model generates high-quality audio that syncs with visual elements in the video. The training set included over a million hours of audio, which allowed the model to pick up on both physical and psychological connections between sound and visuals. They enhanced this model through supervised fine-tuning, using selected high-quality audio and text pairs. This process helped it generate realistic ambient sounds, synced sound effects, and mood-aligned background music for different video scenes.
It follows earlier projects like Make-A-Scene and the Llama Image models, which focused on high-quality image and animation generation.
This release marks the third major milestone in Meta’s generative AI journey and underscores the company’s commitment to pushing the boundaries of media creation tools.
Launching on Insta in 2025
Set to debut on Instagram in 2025, Movie Gen is poised to make advanced video creation more accessible to the platform’s wide range of users.
While the models are currently in a research phase, Meta has expressed optimism that Movie Gen will empower users to produce compelling content with ease.
As the product continues to develop, Meta intends to collaborate with creators and filmmakers to refine Movie Gen’s features and ensure it meets user needs.
Meta’s long-term vision for Movie Gen reflects a broader goal of democratizing access to sophisticated video editing tools. While the suite offers considerable potential, Meta acknowledges that generative AI tools like Movie Gen are meant to enhance, not replace, the work of professional artists and animators.
As Meta prepares to bring Movie Gen to market, the company remains focused on refining the technology and addressing any existing limitations. It plans further optimizations aimed at improving inference time and scaling up the model’s capabilities. Meta has also hinted at potential future applications, such as creating customized animated greetings or short films entirely driven by user input.
The release of Movie Gen could signal a new era for content creation on Meta’s platforms, with Instagram users among the first to experience this innovative tool. As the technology evolves, Movie Gen could become a vital part of Meta’s ecosystem and that of creators — pro and indie alike.
Source link





